前言
随着对stm32以及其RTOS的深入,我逐渐意识到要真正深刻地了解其工作原理,对其cortex-m内核的了解是必须的。因此,我在学习过程中编写了如下笔记,希望能对后人有所帮助。
ARM架构内核发展史
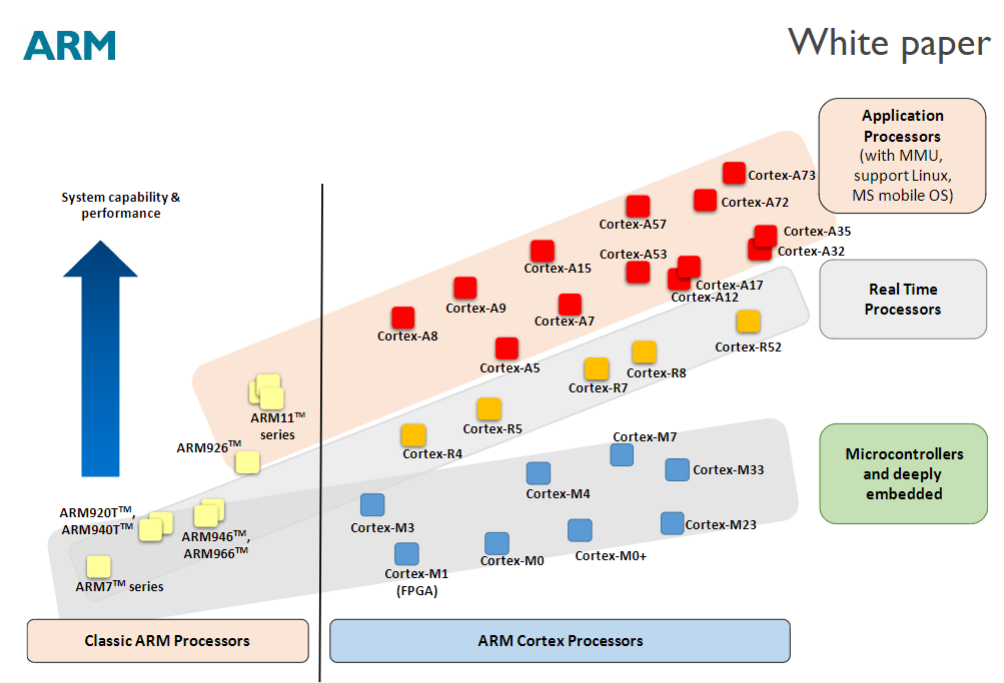 正如上图所见,多年来,ARM 开发了众多不同的处理器产品。ARM 处理器分为经典 ARM 处理器和较新的 Cortex 处理器产品系列。这些处理器根据应用领域又分为三组:
正如上图所见,多年来,ARM 开发了众多不同的处理器产品。ARM 处理器分为经典 ARM 处理器和较新的 Cortex 处理器产品系列。这些处理器根据应用领域又分为三组:
应用处理器——用于移动计算、智能手机、服务器等的高端处理器。这些处理器运行在更高的时钟频率(超过 1GHz),并支持内存管理单元 (MMU),这是 Linux、Android、MS Windows 等全功能操作系统和移动操作系统所必需的。
实时处理器——这类处理器性能极高,适用于实时应用,例如硬盘控制器、汽车动力传动系统和无线通信中的基带控制。大多数这类处理器没有 MMU(内存管理单元,后面搞懂了再讲),通常具有内存保护单元 (MPU)、缓存和其他专为工业应用设计的内存功能。它们可以以相当高的时钟频率运行(例如 200MHz 至 1GHz 以上),并且响应延迟极低。虽然这些处理器无法运行完整版 Linux 或 Windows,但许多实时操作系统 (RTOS) 可以与这些处理器兼容。 (实际上很多裁剪的Linux都可以运行)
微控制器处理器——这类处理器通常设计得更小,硅片面积更小,能效更高。STM32等就属于这个行列。通常情况下,它们的流水线(这是CPU设计中的东西,pipline)更短,最大频率也更低(尽管有些处理器的运行频率超过 200MHz)。同时,较新的 Cortex-M 处理器系列设计得非常易于使用,因此在微控制器和深度嵌入式系统市场非常受欢迎。
常见Cortex-M架构的单片机
这里只介绍我们用的Cortex-M4架构的(不同代之间可能指令集,架构都不同,所以介绍其他的没有必要)
比较著名的单片机供货商都使用了Cortex-M4,比如意法半导体的:
STM32F4 系列:STM32F401, STM32F407, STM32F429, STM32F446 等
Texas Instruments(德州仪器)的:
TM4C 系列(原 Stellaris LM4F):TM4C123, TM4C1294 等
Cortex-M4的特性
我们使用的cortex-m4支持DSP(数字处理拓展),F4更是有FPU单元。这些后面会讲到,现在先关注其最大的特点:异常处理。
cortex-m内核有两种操作模式,thumb模式和调试模式。thumb模式下,系统会正常执行代码,并且在出现异常的时候跳转到异常处理模式,直到异常返回才会继续运行。调试模式下,程序会暂停,直到调试器控制退出暂停,返回thumb模式。
这个调试模式的暂停,一般就是keil等调试时候打的断点。而异常处理部分值得一看,这个“异常”并非Erro报错等,而是将ISR中断等,被视作普通代码外的“异常”。(其实硬件错误也是异常,不过尚不清楚关系,这里只讨论中断异常)
内核是通过三个优先级来进行在普通代码,启动代码和异常处理之间切换的。普通代码属于一般优先级,启动代码属于特权优先级,异常处理属于特权处理优先级,其关系是:一般<特权<特权处理。这保证了NVIC中断向量表等关键寄存器不被普通代码篡改。
因此,FreeRTOS等RTOS可以不用担心用户对内核寄存器的破坏,保证其调度在高优先级(除了中断,依然可以打破其优先级)
这个方法可以用来控制代码权限,比如写一个串口下载程序,其在完全下载完成校验完成后才会提升到更高权限层,并被允许写入flash,以避免升级出错导致系统崩溃。
实际的运用
你可能会问:我知道有这个中断有啥子用嘞?
确实没啥用
好吧,其实这和FreeRTOS这种RTOS的核心原理息息相关。我们知道,内存分为栈,堆,和共享空间。在实际的储存中,代码是跑在一整段的连续内存中的,这段内存就被称为控制块,也叫PCB(不是电路板那个PCB)/TCB (Task Control Block,任务控制块),前者在Linux里常见,后者一般出现在我们常用的FreeRTOS里。这里只讲TCB(二者有区别的,具体实现上完全不一样,但是思想是类似的)
TCB由多部分组成,大概可以粗分为三部分,一部分是储存栈顶指针,上下文寄存器,一部分是储存任务名和各种参数。还有一部分储存的是我们的任务代码。
我们知道我们要计算一个东西就得把他的值丢进寄存器里然后过加法乘法啊什么的加法器乘法器算出来。还有很多东西需要写到各种寄存器里,但是我们的任务是一直在互相抢来抢去的,前一个任务写入的寄存器可能对于后一个任务来说就是无用的甚至有害的垃圾值,并且后一个任务重写的寄存器也会导致切回原来的任务时出现各种问题。为了实现真正的多线程,这些OS很好的利用了内核的中断机制:
在发生异常的时候,内核会自己将常用的寄存器压入栈内,这个称为硬件自动状态保存。接下来就会进入异常处理的代码,这段代码被OS控制,然后OS会手动把更多的任务上下文细节保存下来,向LR(link register)压入一个特殊值,使得硬件感知到异常处理结束。在这个过程中,任务运行的指针已经被OS偷偷换掉了,因此CPU完全不会意识到什么不对,而各种寄存器的问题也已经被OS在异常中断中解决了。
压栈的具体细节
简单来说,这个过程是由硬件和底层汇编代码共同完成的。当任务切换发生时(通常由一个叫 PendSV 的异常触发):
- 硬件代劳: 内核会自动把一些核心寄存器(像
xPSR,PC,LR之类的)丢进当前的栈。 - 人工搬运: OS 的底层代码会把剩下的寄存器(
R4-R11)也压进去。 - 换手: 把当前任务的栈指针存到它的 TCB 里,然后把下一个要运行的任务的栈指针拉出来送给 CPU。
- 出栈: 逆序把上个任务存的东西全部弹出来。
这样,CPU 就像“失忆”后再“重启”一样,它甚至不知道自己刚才去跑了别的任务,直接从上次停下的地方继续算。
双堆栈机制:MSP 与 PSP
你可能会吐槽:如果中断嵌套了,或者任务把栈搞崩了,内核不也跟着挂了? 这时就不得不提 Cortex-M 的设计。它准备了两个“口袋”:
- MSP (Main Stack Pointer): 给主程序、内核和中断服务程序(ISR)用的,它是BIGBOSS,保证系统最核心的玩意儿不出事。
- PSP (Process Stack Pointer): 专门给用户任务用的。
在 FreeRTOS 下,任务运行在 PSP 模式,而中断处理运行在 MSP 模式。这样哪怕你的任务代码写得再烂导致栈溢出,也不会直接把内核的中断向量表给冲掉,大大提高了系统稳定性。
这个思想和linux的内核态/用户态有类似之处,只不过其没有直接从内存访问权限级别去限制,而是在任务栈层面控制
拓展知识
https://hdu-cs.wiki/10.%E7%A1%AC%E4%BB%B6%E6%A8%A1%E5%9D%97/10.3%20%E8%A3%B8%E6%9C%BA%E4%BB%8B%E7%BB%8D/10.3.2%20STM32/10.3.2.4%20%E4%BD%93%E7%B3%BB%E6%9E%B6%E6%9E%84/10.3.2.4.2%20Cortex_M%E5%86%85%E6%A0%B8%E7%BB%93%E6%9E%84.html 一文基本介绍了各个内核寄存器以及优先级,中断异常处理机制等等。 https://blog.csdn.net/weixin_55672545/article/details/130453893 则快速建立了内核架构的概念。 https://zhuanlan.zhihu.com/p/1971233743923573817 讲述了PenSV的机制